I noticed that standard avatars in Vircadia have a kind of lip-synch which is working when talking, and this works as well with with readyplayerme. They all seems to have a special skeleton and kind of poses to work with teeth to perform that lip-synch.
It appears that metaverse-tool hifi skeleton is not apparently doing this and avatars made with it coming from mixamo or makehuman dont appear to have moving lips.
Is there something we missed in the usage of metaverse-tool that would create such lip/mouth moving effect when speaking and usable by non technical people like my students in current vircadia class I’m holding? BTW: Vircadia is currently quite welcomed from my class. The 40 participants did enjoy private servers on their pc and unlimited new educational possibilities
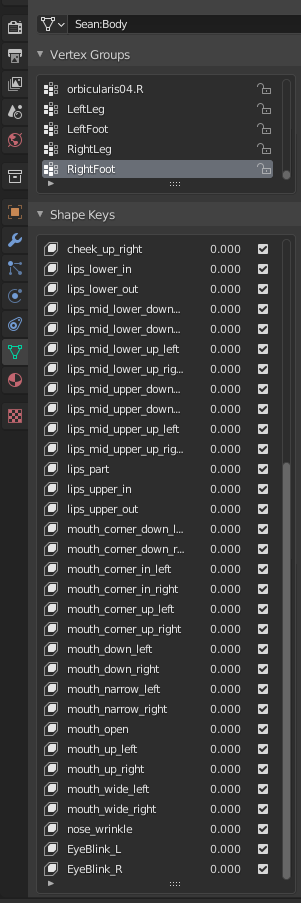
In order to make the mouth move you have to use what’s called blendshapes or shapekeys (two words for the same thing). Basically someone has to edit the position of the vertices in a tool like blender, and save the state of said vertices. The most basic shapekey/bladeshape for mouth movement The Hifi Engine/Vircadia supports is “JawOpen”
The way to do this is to go into blender, find the Shape Keys panel on the Object Data Properties. Add a shapekey (this will be called default automatically, add a second shapekey and name it JawOpen. With JawOpen highlighted, go back to the 3d window and start moving vertices around in edit mode. Just a reminder, you shouldn’t try to add blendshapes until absolutely everything else on your model is finished and ready to go, as you’ll probably have to redo them.
Note: Last I’d checked, mixamo models do not have built-in shape keys, and if you try to rig an object in mixamo, I believe any existing shape keys on that model will be removed in the process. I forgot if makehuman does or does not have this built in. But for any model that does (and you can check in the shape keys section when you import the model into blender) you may have to rename them to be compatible.
More info on shapekeys/blendshapes can be found here
Thanks a lot for your answer. I understand it is not trivial, but at least there is a viable workflow that I can manage to document in a video for my students. I will try to put your instructions written in detailed steps and possibly publishing here. I think many people educators can find it quite a huge steps for them for doing simple historical videos from Vircadia without spending so much money in tools for lipsyncing.
One of my students did actually do in the past some very nice similar videos like this one: Piazza del Lago fra tradizione, Storia e Letteratura - YouTube the voices belong to his secondary school students.
If I am not wrong he did these animations in Unity, but they can be easily be ported in a more friendly Vircadia environment.
Dear Salahzar and Dear Aitolda,
thank you both so much for the advices. Special thanks to Salahzar, he is a great professional, with a marked availability, and the information material he proposes is a great stimulus.
@Aitolda … It took me more than 1 month to put in practice your suggestion and it is working.
See here Far muovere le labbra in vircadia con ShapeKey
I’m very happy about this and it seems quite easy to do. Thanks for the instructions.
However I still have some difficulty in understand which and how they are piloted by Vircadia:
the official fbx avatar from arcadia is able to move lips, but does not have JawOpen shape keys, instead it has a moltitude of various other shapekeys, so it appears that the lip moving effect can be obtained by multiple shapekeys.
Following the last link you provided, all these shapekeys are apparently listed, but no specific tutoring is provided on how to use them. Maybe the JawOpen is the simplest workflow you suggested for simplicity, and the other shapekeys are to be used for more complex things.
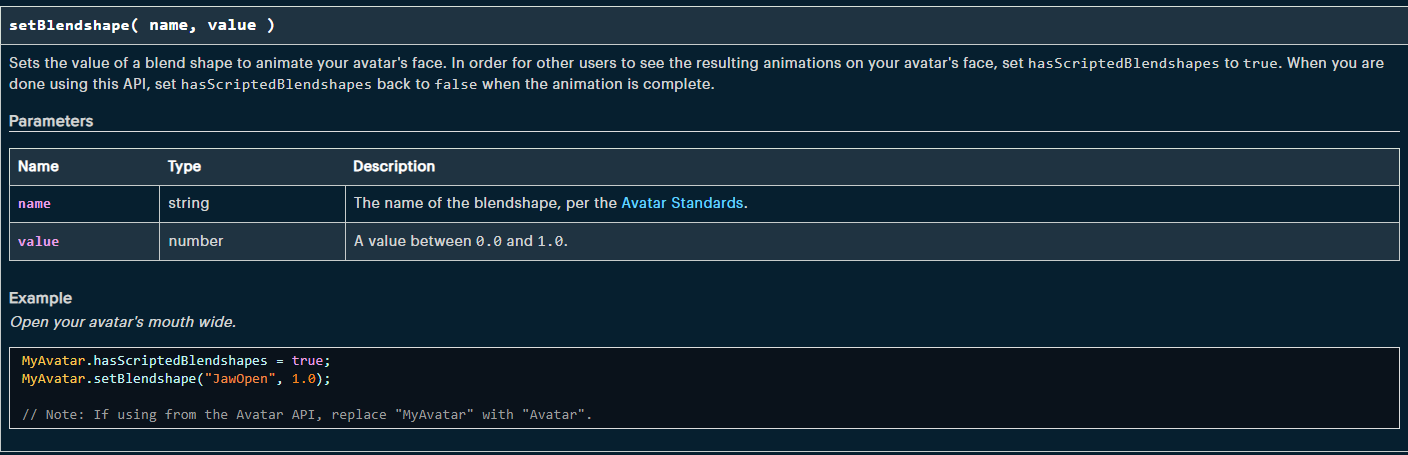
Hi, as told before I did succeed in having avatar moving mouth while speaking. Can I ask how to make lips move in a model via script ? The idea is to have the model as an avatar, when touching it (or just going close to them) having it play a recorded talk, and having the mouth following the audio level produced. I think this can be solved getting the level of some variable, but I am quite confused which variable or method to call. I suppose that it can be something like inputLevelChanged or even investigate on inputSamples and then move accordingly the shapekey using setShapeKey on the model. Does anybody try this thing on a recorded scene?